HBase——Hadoop Introduce
这算是一篇Hadoop的八卦,干货不多。
Hadoop历史
在介绍Hadoop之前,我们先来看看Hadoop的历史,这样能够更好的理解Hadoop的来龙去脉。
Hadoop之父
要说Hadoop的历史,我们不能不先说Hadoop之父Doug Cutting。说到Doug Cutting知道的人可能不多,但是说到他发起的Lucence,可能知道的人就多了。为了能够还清助学贷款以及为以后的生活考虑,Cutting决定开始从事IT相关的工作。1985年,Cutting毕业于美国斯坦福大学,加入Xerox(施乐)公司。说道施乐公司大家未必知道,但是如果告诉大家是施乐发明的东西,大家就会知道了:
- 第一台PC
- 最先发明了图形用户界面,乔布斯就是从施乐那里偷的图形用户界面的概念
- 最先发明了所见即所得文字处理程序
- 发明了因特网
就可见施乐公司有多么牛b,施乐对Cutting后来研究搜索技术起到了决定性的影响。在施乐的这段时间让他在搜索技术的知识上有了很大提高。他花了四年的时间搞研发,这四年中,他阅读了大量的论文,同时,自己也发表了很多论文,用Cutting自己的话说——“我的研究生是在Xerox读的。”
Hadoop的历史
在积累了多年的搜索技术之后,与1997年开始,Cutting决定每周拿出两天的时间来用Java做一个全文文本搜索的开源函数库,这就是非常著名的Lucence。
2004年,Cutting和同为程序员出身的Mike Cafarella决定开发一款可以代替当时的主流搜索产品的开源搜索引擎,这个项目被命名为Nutch。Nutch的目标试图以Lucene为核心建立一个完整的Web搜索引擎,Nutch为HTML提供了解析器,网页抓取工具、链接图形数据库和其他网络搜索引擎额外组件,Cutting设想Nutch是开发和民主的,代替Google等商业产品的垄断。但是在开发过程中,他们遇见了一个问题——如何存储大量网站资料。
不过好在天无绝人之路,Google3篇论文横空出世:
- 2003年在SOSP发布: “Google File System”
- 2004年在OSDI发布: “MapReduce: Simplifed Data Processing on Large Cluster”
- 2006年在OSDI发布: “Bigtable: A Distributed Storage System for Structured Data”
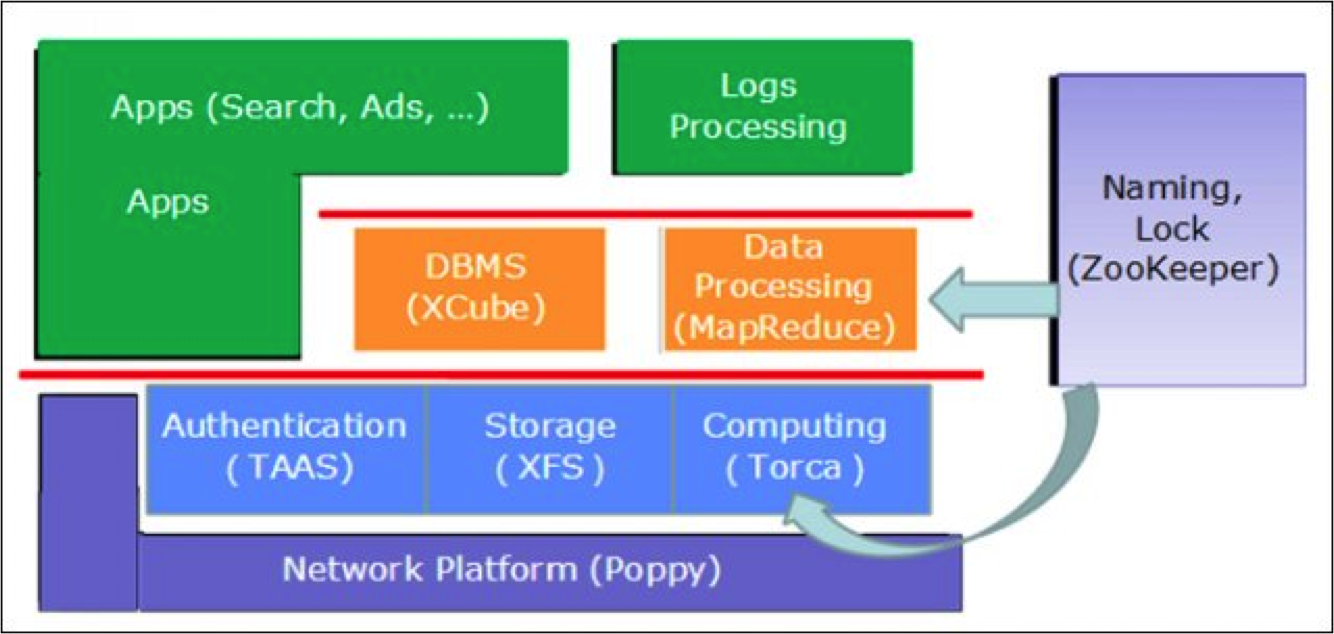
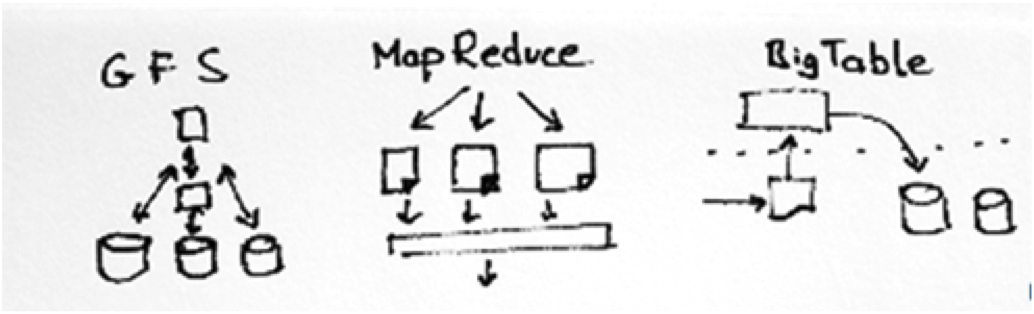 这三个系统被誉为Google的 三驾马车,是Google发展至今的基石。互联网的发展日新月异,但十年前的这三个系统至今在Google内部仍广泛使用,同样这三篇论文对互联网公司的帮助是巨大的。国内的公司也针对这三篇论文有相应的实现,比如腾讯的Typhoon:
这三个系统被誉为Google的 三驾马车,是Google发展至今的基石。互联网的发展日新月异,但十年前的这三个系统至今在Google内部仍广泛使用,同样这三篇论文对互联网公司的帮助是巨大的。国内的公司也针对这三篇论文有相应的实现,比如腾讯的Typhoon:
以及淘宝的飞天:
2004年,Doug Cutting和他的团队根据Google发布的论文实现了一个新的框架,将Nutch移植上去,这种实现马上提上了Nutch的扩展性,能够处理几亿个网页,并能运行在几十个节点的集群上。Cutting认识到涉及一个专门的项目可以充实两种网络扩展所需的技术,就有了Hadoop:
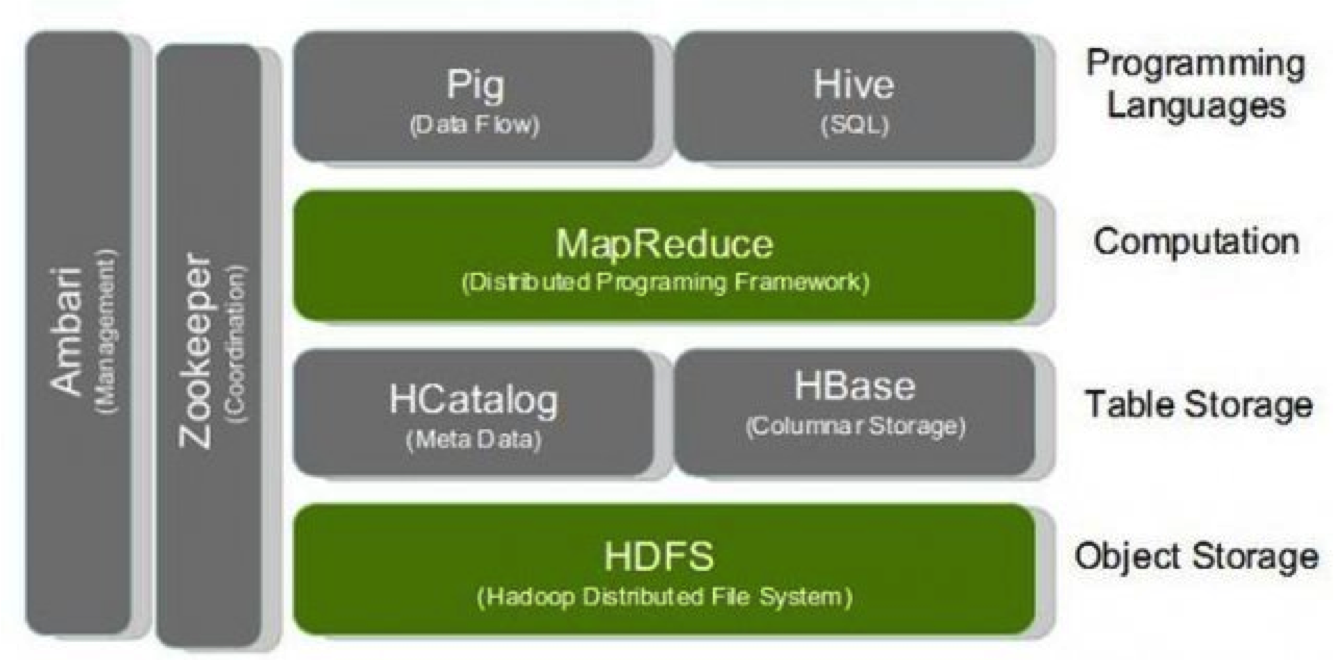
在Nutch0.8的时候,Hadoop成为Apache的顶级项目,逐渐走入到人们的视野。2006年,又在Hadoop项目下添加了Google的BigTable的实现——HBase(关于HBase的介绍放在后面)。
2006年左右,Cutting决定找一家靠谱的公司,进一步完善Hadoop,面试了几家公司都不合适,最后加入了Yahoo!有一支一百多人的团队帮助他完善Hadoop项目。不久之后,Yahoo就宣布将旗下的搜索业务的架构迁移到Hadoop上来。两年之后,Yahoo便基于Hadoop启动了第一个应用项目webmap(一个用来计算网页间链接关系的算法)。让其反应速度在同样硬件环境下提升了33倍
虽然Hadoop的表现惊艳,但在当时并非所有公司都有条件使用,与此同时,用户需求却在日益增加。有些大公司(如银行、电信公司、大型零售商等)只关注于产品,却不想在技术工程和咨询服务上过多投入,它们需要一个可以帮助其解决问题的平台,于是2009年Cutting跳槽到Cloudera,继续开发Hadoop。
Hadoop的来历
Hadoop的logo是一只黄色的小象:
![]()
这只黄色的小象是Cutting孩子的玩具。其实这已经不是第一次Cutting使用跟家人相关的名词来命名他的项目了:
- Lucence是Cutting妻子的中间名字
- Nutch是Cutting孩子说Lunch时的发音
- Hadoop是Cutting孩子的玩具名
Hadoop简介
谁在使用Hadoop
在国内,包括中国移动、百度、网易、淘宝、腾讯、金山和华为等众多公司都在研究和使用它,在国外Yahoo!、FaceBook、IBM等公司都在使用Hadoop,你可以从这里找到更详细的使用Hadoop的公司列表。
目前Hadoop在Yahoo!中的使用情况如下:
- 应用于Yahoo的各种产品,包括数据分析、内容优化、反垃圾邮件系统、广告的优化选择、大数据处理和ETL以及用户兴趣预测、搜索排名、广告定位等方面。
- 2008年9月的时候,超过4000个节点,30000个核,处理超过16P的数据
什么是Hadoop
说到Hadoop的定义,就要分为:
- 狭义的Hadoop
- 广义的Hadoop
狭义的Hadoop
一般来说狭义的Hadoop指的就是只包括:
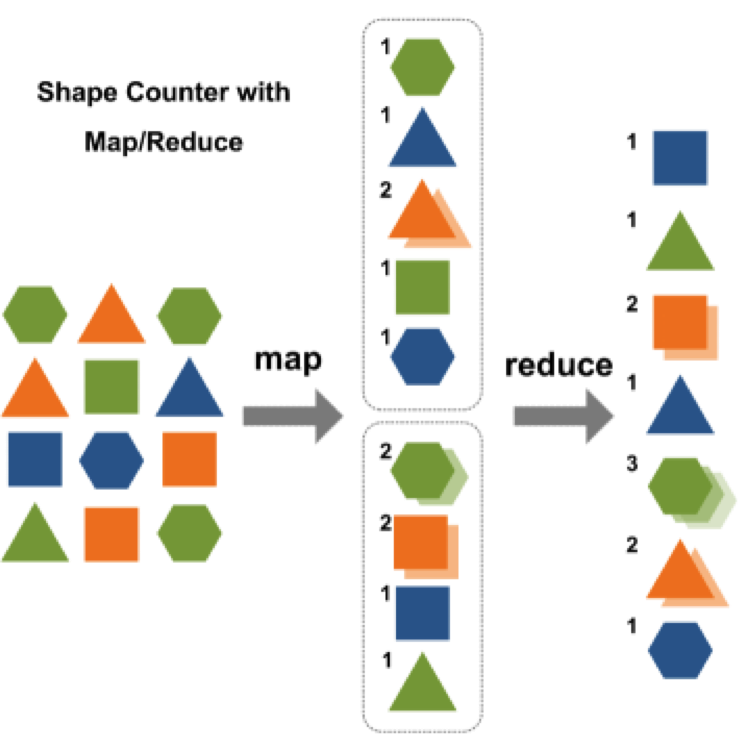
- MapReduce——实现MapReduce: Simplifed Data Processing on Large Cluster的一个分布式计算框架。下面就是一个关于计算图形个数的例子,我在另外一篇文章中详细解释了MapReduce的过程。
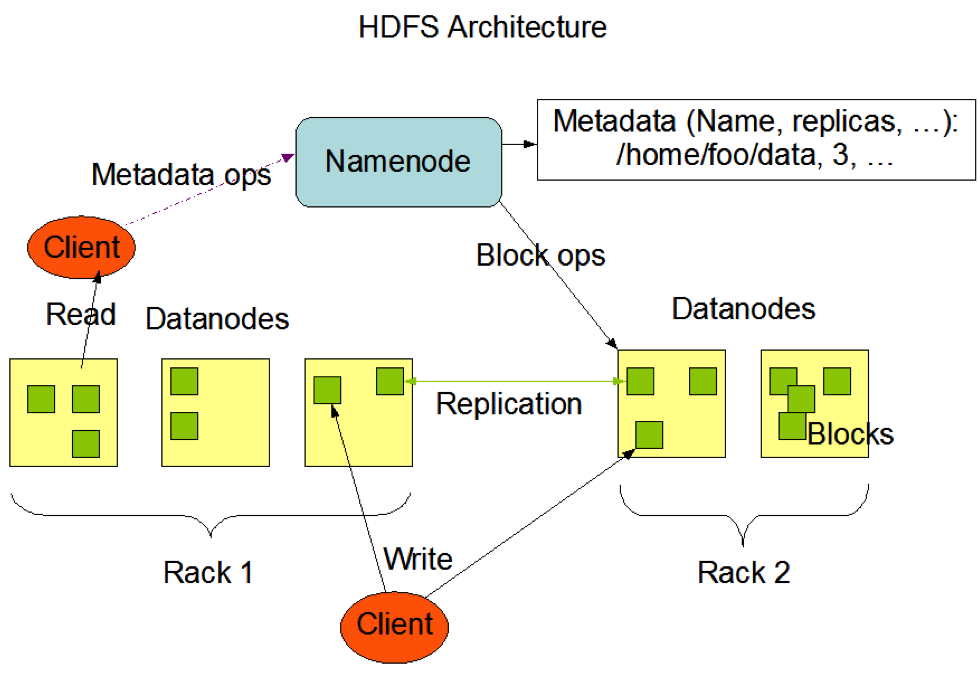
- HDFS——实现Google File System的分布式文件系统
广义的Hadoop
广义的Hadoop,一般称为Hadoop生态系统,起定义为:
1
| |
翻译为中文就是:
1
| |
注意到没有,给Hadoop的定义是一个platform,一个平台。
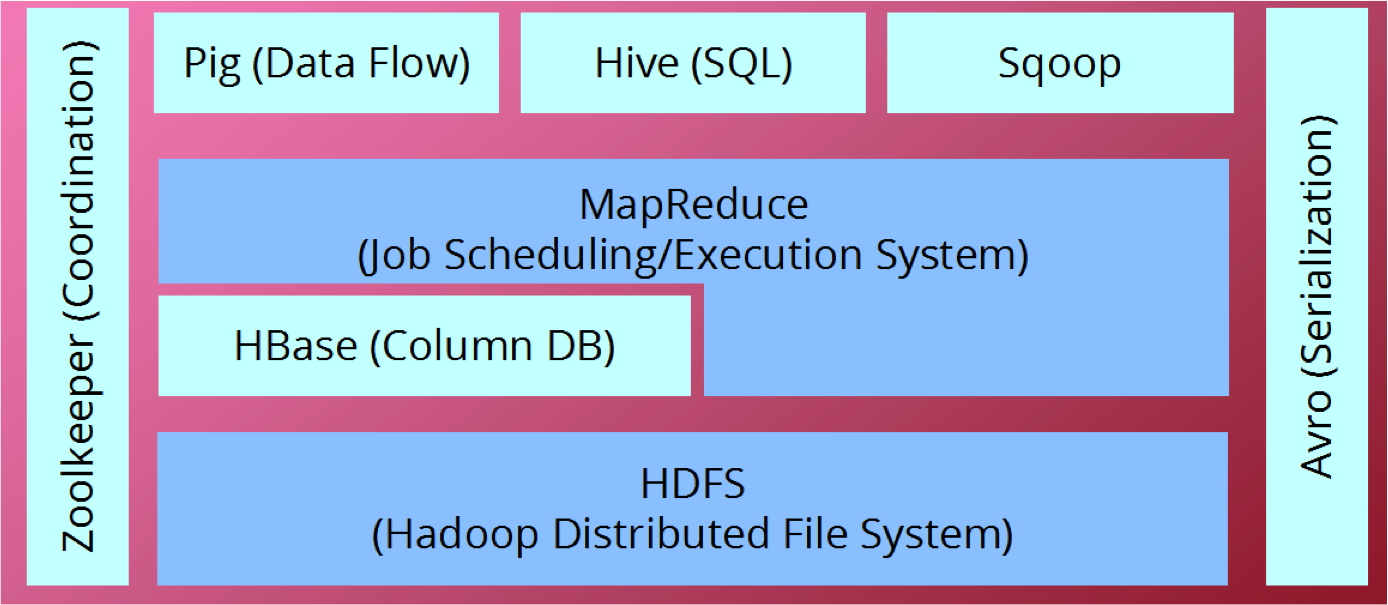
下面大概说一下Hadoop这个平台上的这些软件的作用:
- HDFS:Hadoop的分布式文件系统,可以看见HBase、MapReduce这些软件是运行在HDFS之上的,可以说是Hadoop生态系统的基石。
- HBase:Google分布式数据库Bigtable的开源实现,这个我们后续的文章中重点介绍。
- MapReduce:分布式计算框架。
- Sqoop:协助RDBMS与Hadoop的Hive和HBase之间进行数据传导的工具。
- Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
- Pig:是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
- ZooKeeper:是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
- Avro:是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输也采用了这个工具。Avro是一个数据序列化的系统。Avro可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。
Summary
Cutting最开初创建Lucence,之后创建搜素引擎Nutch。但是因为搜索引擎需要抓取大量的网页,所以需要一个分布式文件系统来存储。同样在有了大量文件之后,就需要一个分布式计算框架来搜索结果,于是乎就有了已经是大数据事实标准的Hadoop。
作为Google三驾马车的开源实现之一——HBase,后续的文章我们会看到HBase都有哪些优点在NoSQL领域称霸。