MapReduce in Hadoop
大数据被大家越来越重视,而在大数据的领域里,Hadoop基本上是行业里的事实标准。而MapReduce又是Hadoop中的一个重要特性,这里总结一下MapReduce相关的特性。
MapReduce的Job是如何工作的
客户端提交一个Job到Hadoop的MapReduce之后,Hadoop的JobTracker(Hadoop集群中的Master)会把任务分发到TaskTracker(Hadoop集群中的slave)上,先执行Map Task,再执行Reduce的任务。大体流程如下图所示:
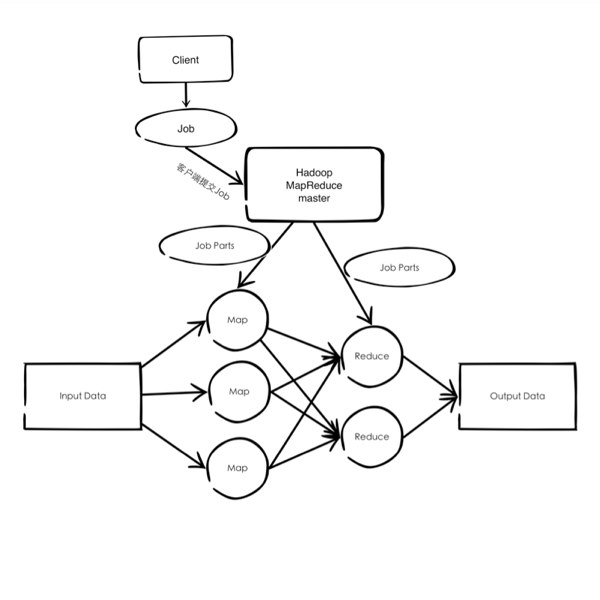
High Level actors in MapReduce
如下图所示:
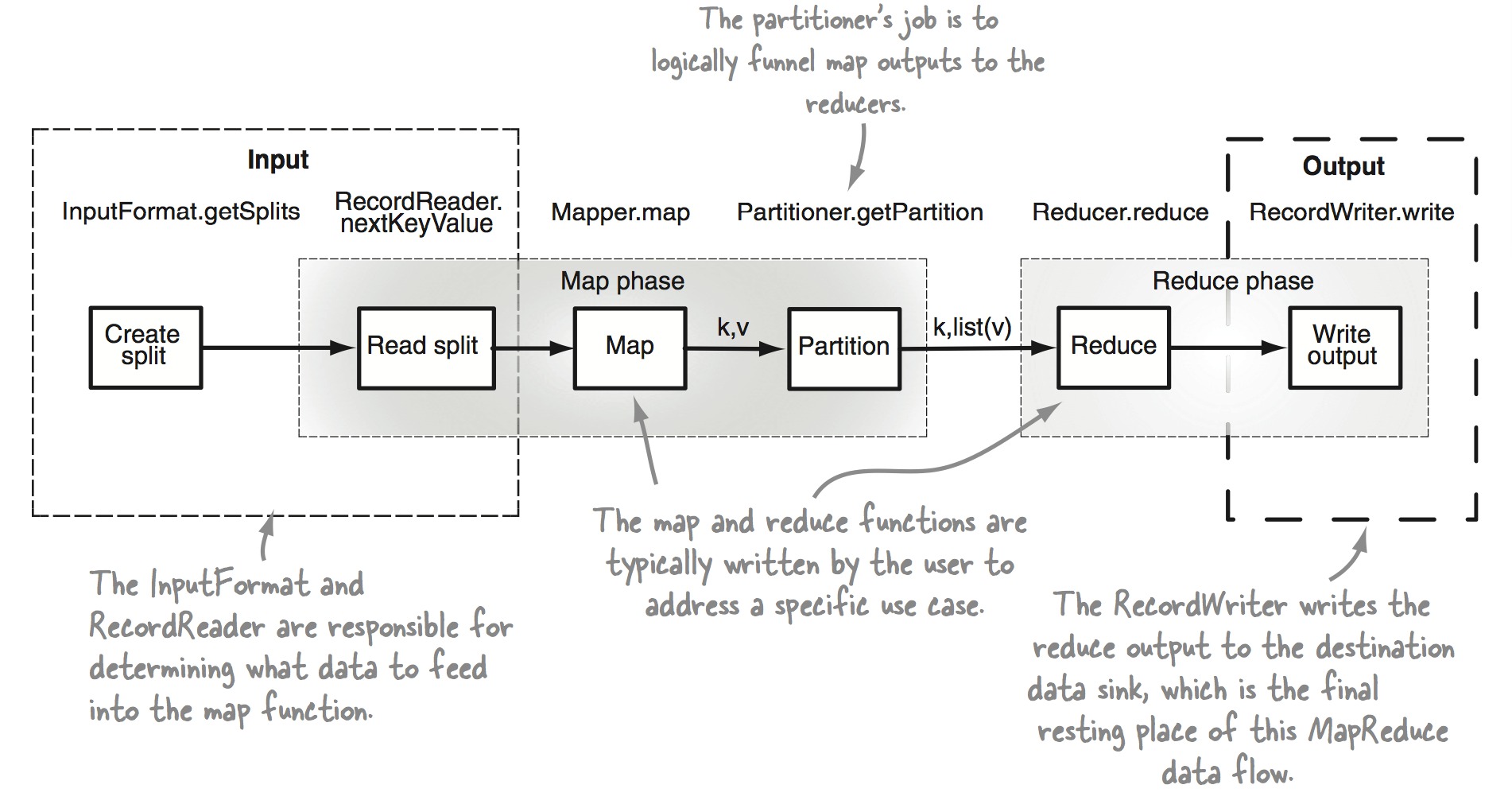 在MapReduce里面分为如下几个方面:
在MapReduce里面分为如下几个方面:
- Input阶段通过InputFormat和RecordReader决定什么样的数据输入到Map中去
- Create split分割Input Data
- Read split通过RecordReader的nextKeyValue为Map输入数据
- Map
- Partitioning阶段把Map的输出进行Shuffle和Sort
- Reduce
- Output阶段将Reduce阶段的输出写到data sink
Map
- 输入:根据split的不同,Map的输入数据可以是文件的一行,也可以是数据库表的一行记录。
- 输出:零个或者多个key、value对。
Shuffle和Sort
在MapReduce里,Map处理完Input Data之后的key、value输出需要通过Shuffle和Sort之后,再将数据传递给Reducer。在Shuffle和Sort阶段有两个任务:
- 决定Reducer应该处理哪些key/value对(被称为partitioning)
- 确定给Reducer的数据是被排过序的
从下图中的例子可以看到,Mapper 1的输出cat, doc1 以及Mapper 2的输出cat, doc2,在经过Shuffle之后被汇总成cat,list(doc1, doc2)。同时,经过Sort之后,传到Reducer里的数据是按照Key排过序的(cat, chipmunk, dog, haster)
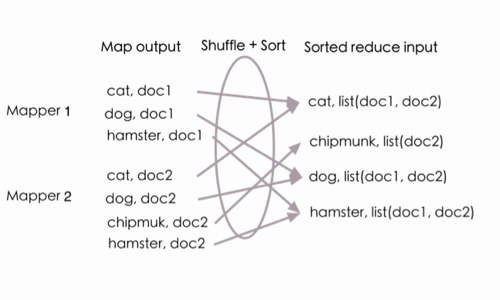
Shuffle好理解,上面已经解释了原因,Sort又耗时又没有意义(因为对于Reduce而言,什么顺序都不会影响结果的),为什么要Sort之后才传给Reduce呢? 经过多方查证,原来在Google的MapReduce论文里就是这样定义的,主要是Google在Reduce之后存储,要是有序的话,查询会更方便些。Hadoop在实现Google的MapReduce论文时,也实现了Sort阶段。
Reduce
处理经过Shuffle和Sort之后的数据,并更具需求输出一个或者多个key/value对。可以输出到HDFS上的一个文件里,也可以输出到NoSQL,或者其他任何Data Sink